LLMs as Judges: Using Large Language Models to Evaluate AI-Generated Text
1. Introduction
The Challenge of Evaluating AI-Generated Text
Imagine you’re a teacher grading thousands of essays, or a company evaluating customer service responses generated by AI. How do you determine which responses are good, which are bad, and which need improvement? This is one of the biggest challenges in artifical intelligence today.
Traditionally, researchers have used mathematical formulas (called metrics like BLEU and ROUGE) to automatically score text. Think of these like spell-checkers – they can catch obvious errors, but they can’t tell if a piece of writing is truly engaging, accurate, or helpful. These traditional methods often miss the nuances that make text truly good: Does it flow naturally? Is it factually correct? Does it actually answer the question asked?
The gold standard has always been human evaluation – having real people read and rate the text quality. This is like having human teachers grade those thousands of essays. While humans are excellent at recognizing good writing, this approach has serious limitations:
- Speed: Humans can only read and evaluate so much text per day
- Cost: Paying human evaluators is expensive, especially for large-scale evaluations
- Consistency: Different humans might rate the same text differently
- Scale: Modern AI systems can generate millions of responses – far more than humans can reasonably evaluate
The Revolutionary Idea: LLMs as Judges
This is where a revolutionary idea emerged: What if we could use advanced AI language models themselves as “judges” to evaluate other AI-generated text? Think of it as having a highly sophisticated AI teacher that can read and grade those thousands of essays instantly.
Modern Large Language Models (LLMs) like GPT-4, Claude, or Llama have developed remarkable abilities:
- Deep Language Understanding: They can comprehend context, nuance, and meaning
- Flexible Reasoning: They can adapt their evaluation criteria based on the specific task
- Detailed Explanations: They can explain why they gave a particular score
- Speed and Scale: They can evaluate thousands of texts in minutes, not days
In practical terms, this means we can ask an advanced AI system questions like:
"Rate this summary on a scale of 1-5 for accuracy and clarity""Which of these two customer service responses is more helpful?""Does this answer actually address the question that was asked?"
Research has shown that when properly instructed, these AI judges can agree with human evaluators at rates aproaching the level at which humans agree with each other. This is remarkable – it suggests that AI can potentially automate one of the most challenging aspects of AI development: evaluation itself.
This shift promises to make evaluation faster, cheaper, and more consistent, while maintaining the quality and insight that only intelligent evaluation can provide. Instead of waiting weeks for human evaluators, researchers and companies can get detailed feedback on their AI systems in hours.
Setting up the Environment
First, let’s set up our Python environment with the necessary dependencies:
# Install required packages
# pip install langchain-ollama langchain-core pandas numpy matplotlib seaborn
import json
import pandas as pd
import numpy as np
from typing import List, Dict, Any, Optional, Tuple
from dataclasses import dataclass
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import JsonOutputParser
import matplotlib.pyplot as plt
import seaborn as sns
# Initialize Ollama with Llama3.2 model
class LLMJudge:
def __init__(self, model_name: str = "llama3.2"):
"""Initialize the LLM judge with Ollama"""
self.llm = OllamaLLM(model=model_name, temperature=0.1)
self.model_name = model_name
def evaluate_text(self, prompt: str) -> str:
"""Evaluate text using the LLM"""
try:
response = self.llm.invoke(prompt)
return response
except Exception as e:
print(f"Error in evaluation: {e}")
return ""
# Initialize the judge
judge = LLMJudge()
The code above creates our AI judge using the Llama 3.2 model. The key parameter here is temperature=0.1, which tells the AI to be more consistent and less creative in its evaluations – exactly what we want when we need reliable, repeatable judgments.
2. Problem Formulation
Understanding How AI Judges Work
To understand how LLMs can serve as evaluators, let’s break down the process in simple terms. Imagine you’re asking a very knowledgeable friend to help you grade papers. You would:
- Give them the assignment instructions (the original question or task)
- Show them the student’s response (the text to be evaluated)
- Explain what makes a good answer (the evaluation criteria)
- Ask for their judgment (score, preference, or detailed feedback)
An LLM-as-judge works exactly the same way, except this “knowledgeable friend” is an AI system that can process information incredibly quickly and consistently apply the same standards to every piece of text it evaluates.
The Three Ways AI Can Judge Text
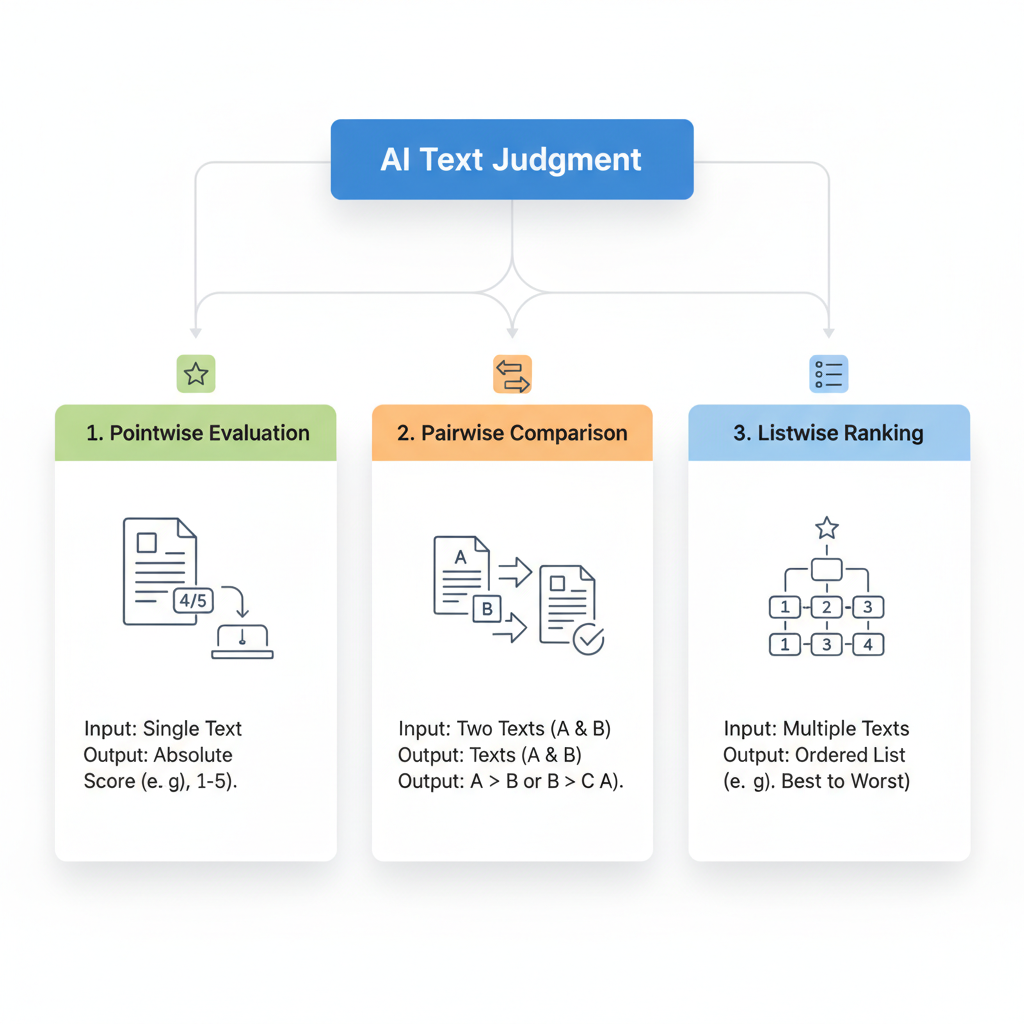
When we ask an AI system to evaluate text, there are three main approaches we can use:
1. Pointwise Evaluation (Individual Scoring) This is like asking a teacher to grade each essay independently on a scale from 1 to 5. The AI looks at one piece of text at a time and assigns it a score based on specific criteria.
Example: "Rate this product review summary for helpfulness: 1 = Not helpful at all, 5 = Extremely helpful"
This approach is great when you need absolute scores and want to evaluate many pieces of text quickly.
2. Pairwise Comparison (Head-to-Head) This is like asking someone “Which is better: Response A or Response B?” Instead of assigning absolute scores, the AI directly compares two pieces of text and tells you which one is superior.
Example: "Which customer service response is more professional and helpful?"
This method works particularly well when the differences between texts are subtle, or when you’re trying to rank options from best to worst.
3. Listwise Ranking (Ordering Multiple Options) This is like asking someone to arrange a set of answers from best to worst. The AI looks at multiple pieces of text simultaneously and ranks them in order of quality.
Example: "Rank these five chatbot responses from most to least helpful"
This approach is valuable when you need to select the best option from many alternatives or understand the relative quality of different responses.
What Makes a Good Evaluation?
Just as a good human teacher considers multiple factors when grading (clarity, accuracy, completeness, etc.), AI judges can evaluate text based on various criteria:
Linguistic Quality: How well is the text written?
Fluency: Does it read naturally and smoothly?Grammar: Are there spelling or grammatical errors?Coherence: Do the ideas flow logically from one to the next?
Content Accuracy: How correct and relevant is the information?
Factual Correctness: Are the facts stated accurately?Relevance: Does the response actually address what was asked?Completeness: Are all important aspects of the topic covered?
Task-Specific Qualities: Depending on the specific use case:
Informativeness: Does a Q&A response provide useful information?Helpfulness: Does a customer service response solve the customer’s problem?Creativity: Does a creative writing piece show originality and imagination?
Reference-Based vs. Reference-Free Evaluation
Sometimes we have a “perfect answer” to compare against (reference-based evaluation), like when students take a test with known correct answers. Other times, we’re evaluating creative or open-ended responses where there’s no single “right” answer (reference-free evaluation), like rating the quality of a creative story or evaluating customer service interactions.
AI judges can handle both situations effectively, adapting their evaluation approach based on whether they have a reference answer to compare against.
Technical Implementation: Building AI Evaluators
The following sections show how to implement these concepts using Python code. Don’t worry if you’re not a programmer – the explanations will help you understand what each piece does and why it’s important.
Setting Up Our AI Judge
First, we need to set up our AI evaluation system. Think of this as preparing our “AI teacher” with the right tools and knowledge to evaluate text effectively.
Building Different Types of Evaluators
Now let’s build our three main types of evaluators, starting with the pointwise evaluator that scores individual pieces of text.
The Pointwise Evaluator: Rating Individual Responses
This evaluator works like a teacher grading individual essays. It looks at one piece of text, considers multiple criteria (relevance, accuracy, clarity, etc.), and assigns both an overall score and individual scores for each criterion. The AI provides detailed reasoning for its scores, making the evaluation transparent and helpful for improvement.
@dataclass
class EvaluationResult:
"""Data class for evaluation results"""
score: int
explanation: str
criteria_scores: Dict[str, int]
evaluation_mode: str
class PointwiseEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
def evaluate_single(self, question: str, answer: str, criteria: List[str]) -> EvaluationResult:
"""Pointwise evaluation of a single answer"""
prompt = PromptTemplate(
input_variables=["question", "answer", "criteria"],
template="""
You are an expert evaluator. Rate the given answer based on the following criteria: {criteria}
Question: {question}
Answer: {answer}
Please provide your evaluation in the following JSON format:
{{
"explanation": "Your detailed reasoning",
"overall_score": 1-5 (integer),
"criteria_scores": {{
"relevance": 1-5,
"accuracy": 1-5,
"clarity": 1-5,
"completeness": 1-5
}}
}}
Rating Scale:
1 - Poor
2 - Below Average
3 - Average
4 - Good
5 - Excellent
"""
)
formatted_prompt = prompt.format(
question=question,
answer=answer,
criteria=", ".join(criteria)
)
response = self.judge.evaluate_text(formatted_prompt)
try:
# Parse JSON response
result_dict = json.loads(response)
return EvaluationResult(
score=result_dict.get("overall_score", 0),
explanation=result_dict.get("explanation", ""),
criteria_scores=result_dict.get("criteria_scores", {}),
evaluation_mode="pointwise"
)
except json.JSONDecodeError:
# Fallback if JSON parsing fails
return EvaluationResult(
score=0,
explanation=response,
criteria_scores={},
evaluation_mode="pointwise"
)
# Example usage
evaluator = PointwiseEvaluator(judge)
The Pairwise Evaluator: Comparing Two Responses Head-to-Head
Sometimes it’s easier to say “Response A is better than Response B” than to assign absolute scores. The pairwise evaluator specializes in direct comparisons, helping you choose the better option when you have multiple alternatives. This is particulary useful for tasks like selecting the best customer service response or choosing between different AI-generated summaries.
class PairwiseEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
def compare_answers(self, question: str, answer1: str, answer2: str) -> Dict[str, Any]:
"""Pairwise comparison of two answers"""
prompt = f"""
Compare the following two answers to the question and determine which is better.
Question: {question}
Answer A: {answer1}
Answer B: {answer2}
Please provide your evaluation in JSON format:
{{
"winner": "A" or "B" or "tie",
"explanation": "Your detailed reasoning",
"confidence": 1-5 (how confident you are),
"criteria_comparison": {{
"relevance": "A", "B", or "tie",
"accuracy": "A", "B", or "tie",
"clarity": "A", "B", or "tie"
}}
}}
"""
response = self.judge.evaluate_text(prompt)
try:
return json.loads(response)
except json.JSONDecodeError:
return {"winner": "error", "explanation": response}
# Example usage
pairwise_evaluator = PairwiseEvaluator(judge)
2.2 Evaluation Criteria
The evaluation criteria can cover different aspects. Common criteria include:
- Linguistic quality (fluency, grammar, coherence)
- Content accuracy (factual correctness, relevance)
- Task-specific metrics (e.g. informativeness in QA, or completeness in summarization)
class CriteriaBasedEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
def evaluate_with_criteria(self,
question: str,
answer: str,
criteria: Dict[str, str]) -> Dict[str, Any]:
"""Evaluate based on specific criteria with detailed descriptions"""
criteria_text = "\n".join([f"- {k}: {v}" for k, v in criteria.items()])
prompt = f"""
Evaluate the following answer based on these specific criteria:
{criteria_text}
Question: {question}
Answer: {answer}
For each criterion, provide a score from 1-4 and explanation:
1 = Poor
2 = Below Average
3 = Good
4 = Excellent
Please respond in JSON format:
{{
"overall_assessment": "your overall evaluation",
"scores": {{
"{list(criteria.keys())[0]}": {{"score": 1-4, "explanation": "..."}},
"{list(criteria.keys())[1]}": {{"score": 1-4, "explanation": "..."}},
...
}},
"total_score": "sum of all scores",
"recommendation": "any suggestions for improvement"
}}
"""
response = self.judge.evaluate_text(prompt)
try:
return json.loads(response)
except json.JSONDecodeError:
return {"error": "Failed to parse response", "raw_response": response}
# Define evaluation criteria
qa_criteria = {
"relevance": "How well does the answer address the specific question asked?",
"accuracy": "Is the information provided factually correct?",
"completeness": "Does the answer cover all important aspects of the question?",
"clarity": "Is the answer clear, well-structured and easy to understand?"
}
criteria_evaluator = CriteriaBasedEvaluator(judge)
3. Methodology
The Art and Science of Asking AI to Judge
Just as different teachers might have different grading styles, the way we ask an AI to evaluate text can dramatically affect the quality and consistency of its judgments. This section explores the “how” of AI evaluation – the techniques and strategies that make the difference between unreliable, inconsistent scores and professional-quality assessments.
Think of this as training your AI judge to be the best possible evaluator. We’ll cover several key areas:
- How to write clear, effective instructions (prompting strategies)
- How to design good scoring systems
- How to provide examples that help the AI understand what you want
- How to get structured, easy-to-use results
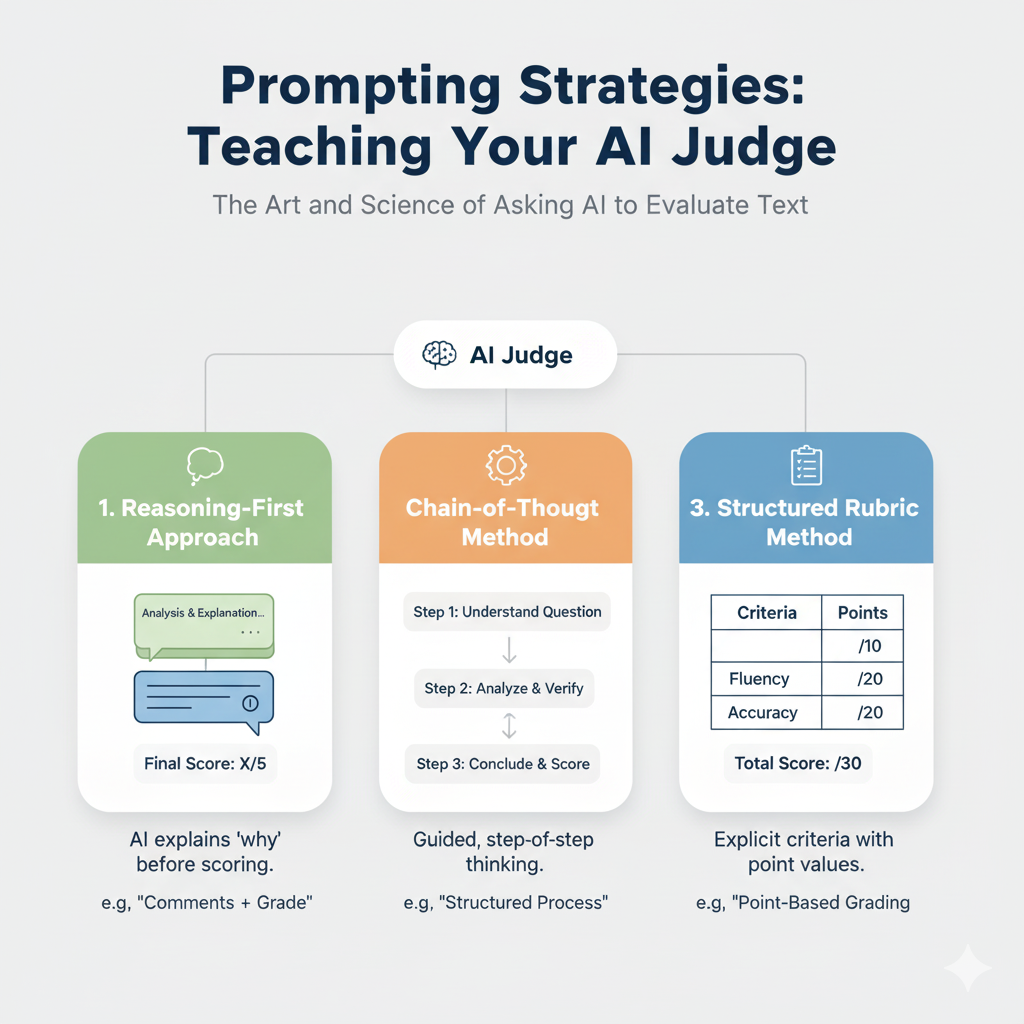
3.1 Prompting Strategies: Teaching Your AI Judge
The way we phrase our requests to the AI judge is crucial. Just like giving instructions to a human assistant, clarity and structure matter enormously. Here are the main approaches that work best:
3.1 Prompting Strategies: Teaching Your AI Judge
The way we phrase our requests to the AI judge is crucial. Just like giving instructions to a human assistant, clarity and structure matter enormously. Here are the main approaches that work best:
1. Reasoning-First Approach This strategy asks the AI to explain its thinking before giving a score. It’s like asking a teacher to write comments before assigning a grade. This approach often leads to more thoughtful, consistent evaluations.
2. Chain-of-Thought Method This breaks down the evaluation into clear, logical steps. Instead of asking for an immediate judgment, we guide the AI through a structured thinking process: understand the question, analyze the answer, check for accuracy, and then conclude with a score.
3. Structured Rubric Method This provides the AI with explicit criteria and point values, similar to how standardized tests are graded. Each aspect of quality gets a specific number of points, and the final score is the sum of these points.
Different prompt formulations can significantly affect an LLM’s judgments. A common structure is to instruct the model to explain its reasoning and then give a score.
class PromptStrategies:
"""Different prompting strategies for LLM evaluation"""
@staticmethod
def reasoning_first_prompt(question: str, answer: str) -> str:
"""Reasoning-first prompting strategy"""
return f"""
You will be given a user_question and system_answer. Provide feedback in this format:
Evaluation: (your rationale)
Total rating: (your rating 1–4)
Question: {question}
Answer: {answer}
Please provide your evaluation following the exact format above.
"""
@staticmethod
def chain_of_thought_prompt(question: str, answer: str) -> str:
"""Chain-of-thought prompting with step-by-step reasoning"""
return f"""
You are evaluating an answer to a question. Think through this step by step:
1. First, understand what the question is asking
2. Analyze what the answer provides
3. Check for accuracy and relevance
4. Consider completeness and clarity
5. Provide your final assessment
Question: {question}
Answer: {answer}
Step-by-step analysis:
1. Question analysis:
2. Answer content:
3. Accuracy check:
4. Relevance assessment:
5. Final rating (1-4):
"""
@staticmethod
def structured_rubric_prompt(question: str, answer: str) -> str:
"""Structured rubric-based evaluation"""
return f"""
Evaluate this Q&A pair using the following rubric:
RUBRIC:
- Award 1 point if the answer is related to the question
- Award 1 point if the answer is clear and well-structured
- Award 1 point if the answer is factually correct
- Award 1 point if the answer is complete and comprehensive
Question: {question}
Answer: {answer}
Evaluation:
Point 1 (Relevance): [0 or 1] - Explanation:
Point 2 (Clarity): [0 or 1] - Explanation:
Point 3 (Accuracy): [0 or 1] - Explanation:
Point 4 (Completeness): [0 or 1] - Explanation:
Total Score: [Sum of points] / 4
Overall Assessment:
"""
# Example usage with different strategies
def compare_prompt_strategies(question: str, answer: str):
"""Compare different prompting strategies"""
strategies = {
"reasoning_first": PromptStrategies.reasoning_first_prompt,
"chain_of_thought": PromptStrategies.chain_of_thought_prompt,
"structured_rubric": PromptStrategies.structured_rubric_prompt
}
results = {}
for strategy_name, prompt_func in strategies.items():
prompt = prompt_func(question, answer)
response = judge.evaluate_text(prompt)
results[strategy_name] = response
print(f"\n{'='*50}")
print(f"STRATEGY: {strategy_name.upper()}")
print(f"{'='*50}")
print(response)
return results
3.2 Score Formats and Few-Shot Examples
Choosing the Right Scoring System
Just as schools might use letter grades (A, B, C, D, F) or percentage scores (0-100%), we need to decide how our AI judge should express its evaluations. Research shows that simpler scoring systems often work better than complex ones.
Why Simple Scales Work Best:
- Easier for the AI to be consistent
- Clearer for humans to interpret
- Less prone to arbitrary distinctions (is there really a meaningful difference between a 7.3 and 7.4 out of 10?)
Most successful implementations use scales like:
- 1-4 scale: Poor, Below Average, Good, Excellent
- 1-5 scale: Poor, Below Average, Average, Good, Excellent
Teaching by Example: Few-Shot Learning
One of the most powerful techniques is showing the AI examples of good evaluations before asking it to evaluate new content. This is like showing a new teacher examples of well-graded papers before they grade their own students’ work.
For example, you might show the AI:
- A high-quality answer that deserves a score of 4, along with an explanation of why
- A medium-quality answer that deserves a score of 3, with reasoning
- A poor-quality answer that deserves a score of 1, with detailed critique
This helps calibrate the AI’s judgment and makes scores more consistant and meaningful.
class FewShotEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
def create_few_shot_prompt(self,
examples: List[Dict[str, Any]],
question: str,
answer: str) -> str:
"""Create few-shot prompt with examples"""
examples_text = ""
for i, example in enumerate(examples, 1):
examples_text += f"""
Example {i}:
Question: {example['question']}
Answer: {example['answer']}
Evaluation: {example['evaluation']}
Rating: {example['rating']}
"""
prompt = f"""
You are evaluating answers to questions. Here are some examples of good evaluations:
{examples_text}
Now evaluate this new example:
Question: {question}
Answer: {answer}
Evaluation: (provide your reasoning)
Rating: (1-4 scale)
"""
return prompt
def evaluate_with_examples(self,
examples: List[Dict[str, Any]],
question: str,
answer: str) -> str:
"""Evaluate using few-shot examples"""
prompt = self.create_few_shot_prompt(examples, question, answer)
return self.judge.evaluate_text(prompt)
# Example few-shot examples
few_shot_examples = [
{
"question": "What is photosynthesis?",
"answer": "Photosynthesis is the process by which plants use sunlight, water, and carbon dioxide to produce glucose and oxygen.",
"evaluation": "The answer correctly defines photosynthesis and mentions the key components (sunlight, water, CO2) and products (glucose, oxygen). It's accurate and concise.",
"rating": 4
},
{
"question": "How do computers work?",
"answer": "Computers are electronic devices.",
"evaluation": "While technically correct, this answer is too brief and doesn't explain how computers actually work. It lacks detail about processing, memory, or basic operations.",
"rating": 2
}
]
few_shot_evaluator = FewShotEvaluator(judge)
3.3 Structured Output Processing
class StructuredOutputEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
self.output_parser = JsonOutputParser()
def evaluate_with_json_output(self, question: str, answer: str) -> Dict[str, Any]:
"""Evaluate with structured JSON output"""
prompt = f"""
Evaluate the following Q&A pair and respond with valid JSON only.
Question: {question}
Answer: {answer}
Required JSON format:
{{
"evaluation": "detailed reasoning about the answer quality",
"scores": {{
"relevance": 1-4,
"accuracy": 1-4,
"clarity": 1-4,
"completeness": 1-4
}},
"total_rating": 1-4,
"strengths": ["list", "of", "strengths"],
"weaknesses": ["list", "of", "weaknesses"],
"suggestions": ["list", "of", "improvement", "suggestions"]
}}
Respond with JSON only, no additional text.
"""
response = self.judge.evaluate_text(prompt)
try:
# Clean the response to extract JSON
response = response.strip()
if response.startswith("```json"):
response = response[7:-3]
elif response.startswith("```"):
response = response[3:-3]
return json.loads(response)
except json.JSONDecodeError as e:
print(f"JSON parsing error: {e}")
return {"error": "Invalid JSON response", "raw_response": response}
structured_evaluator = StructuredOutputEvaluator(judge)
4. Experimental Setup
Testing AI Judges: How Do We Know They Work?
Before trusting an AI system to evaluate text at scale, we need rigorous testing to ensure it works reliably. This is similar to how new medical treatments undergo clinical trials, or how new teachers are observed and evaluated before gaining tenure.
The key question we’re trying to answer is: “Do AI judges agree with human experts often enough to be trustworthy?”
To answer this, researchers have developed systematic ways to test AI evaluation systems using established datasets where human experts have already provided “ground truth” evaluations.
4.1 The Testing Process
Here’s how researchers typically validate AI evaluation systems:
- Start with Human-Evaluated Data: Use datasets where human experts have already scored or ranked text quality
- Have the AI Judge Evaluate the Same Texts: Run the AI system on the exact same examples
- Compare the Results: Measure how often the AI agrees with the human experts
- Look for Patterns: Identify where the AI performs well and where it struggles
The goal isn’t perfect agreement (even human experts don’t always agree with each other), but rather agreement levels that approach the consistency we see between different human evaluators.
4.1 Benchmark Datasets
Researchers use several well-established datasets to test AI evaluation systems. Think of these as “standardized tests” for AI judges:
| Task | Benchmark | Description and Key Metrics |
|---|---|---|
| Summarization | SummEval | 100 news articles with summaries from 16 models. Rated (1–5) on coherence, consistency, fluency, relevance |
| Dialogue/Q&A | MT-Bench | 3K multi-turn instruction/QA questions for conversational ability testing |
| Chatbot Preference | Chatbot Arena | 30K pairwise comparisons via crowdsourced “duels” |
| Instruction Following | AlpacaEval | 20K human preferences on instruction-following test set |
| Code Generation | HumanEval | 164 Python programming problems with unit tests |
| Code Generation | SWEBench | 2,294 coding tasks measuring code correctness |
class BenchmarkEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
self.results = []
def evaluate_dataset(self, dataset: List[Dict[str, Any]]) -> pd.DataFrame:
"""Evaluate a dataset and return results as DataFrame"""
results = []
for i, item in enumerate(dataset):
print(f"Evaluating item {i+1}/{len(dataset)}")
# Get LLM evaluation
llm_result = structured_evaluator.evaluate_with_json_output(
item['question'],
item['answer']
)
# Combine with ground truth if available
result = {
'question': item['question'],
'answer': item['answer'],
'llm_score': llm_result.get('total_rating', 0),
'llm_evaluation': llm_result.get('evaluation', ''),
'human_score': item.get('human_score', None),
'llm_scores_detail': llm_result.get('scores', {})
}
results.append(result)
return pd.DataFrame(results)
def calculate_agreement_metrics(self, df: pd.DataFrame) -> Dict[str, float]:
"""Calculate agreement metrics between LLM and human scores"""
if 'human_score' not in df.columns or df['human_score'].isna().all():
return {"error": "No human scores available for comparison"}
# Remove rows with missing scores
valid_df = df.dropna(subset=['llm_score', 'human_score'])
if len(valid_df) == 0:
return {"error": "No valid score pairs found"}
# Calculate correlation
pearson_corr = valid_df['llm_score'].corr(valid_df['human_score'], method='pearson')
spearman_corr = valid_df['llm_score'].corr(valid_df['human_score'], method='spearman')
# Calculate exact agreement
exact_agreement = (valid_df['llm_score'] == valid_df['human_score']).mean()
# Calculate agreement within 1 point
within_1_agreement = (abs(valid_df['llm_score'] - valid_df['human_score']) <= 1).mean()
return {
'pearson_correlation': round(pearson_corr, 3),
'spearman_correlation': round(spearman_corr, 3),
'exact_agreement': round(exact_agreement, 3),
'within_1_agreement': round(within_1_agreement, 3),
'sample_size': len(valid_df)
}
# Example synthetic dataset for testing
synthetic_dataset = [
{
"question": "What are the benefits of exercise?",
"answer": "Exercise improves health, strengthens muscles, and helps maintain weight.",
"human_score": 3
},
{
"question": "Explain machine learning",
"answer": "Machine learning is when computers learn patterns from data to make predictions or decisions without explicit programming.",
"human_score": 4
},
{
"question": "What is the capital of France?",
"answer": "The capital of France is Paris, which is also its largest city and cultural center.",
"human_score": 4
}
]
benchmark_evaluator = BenchmarkEvaluator(judge)
5. Results
How Well Do AI Judges Actually Perform?
After extensive testing across multiple domains and datasets, the results are quite encouraging. AI judges, when properly designed and implemented, can achieve remarkable agreement with human evaluators – often matching or approaching the level of agreement between different human experts.
5.1 The Key Findings
Agreement Levels Are Impressive
Studies consistently show that advanced AI judges (like GPT-4) agree with human evaluators 80-85% of the time on many tasks. To put this in perspective, human evaluators typically agree with each other about 75-90% of the time, depending on the task complexity and evaluation criteria.
The Technology Keeps Improving More recent and powerful AI models tend to perform better as judges. This suggests that as AI technology continues to advance, we can expect even better evaluation capabilities.
Some Tasks Work Better Than Others AI judges perform exceptionally well on certain types of evaluation:
- Objective criteria: Factual accuracy, relevance to the question
- Clear quality indicators: Grammar, coherence, completeness
- Comparative tasks: “Which response is better?” often works better than absolute scoring
They face more challenges with:
- Highly subjective criteria: Creative quality, humor, emotional impact
- Domain-specific expertise: Medical, legal, or highly technical content
- Cultural nuances: Content that requires deep cultural understanding
5.1 Correlation with Human Judgments
Let’s look at the specific numbers and what they mean in practical terms.
def analyze_llm_human_correlation(results_df: pd.DataFrame):
"""Analyze and visualize LLM-human correlation"""
# Calculate agreement metrics
metrics = benchmark_evaluator.calculate_agreement_metrics(results_df)
print("Agreement Metrics:")
print("=" * 40)
for metric, value in metrics.items():
print(f"{metric}: {value}")
if 'error' not in metrics:
# Create visualization
plt.figure(figsize=(12, 4))
# Subplot 1: Scatter plot
plt.subplot(1, 3, 1)
plt.scatter(results_df['human_score'], results_df['llm_score'], alpha=0.6)
plt.xlabel('Human Score')
plt.ylabel('LLM Score')
plt.title('LLM vs Human Scores')
plt.plot([1, 5], [1, 5], 'r--', alpha=0.5) # Perfect agreement line
# Subplot 2: Score distribution
plt.subplot(1, 3, 2)
plt.hist(results_df['human_score'], alpha=0.5, label='Human', bins=5)
plt.hist(results_df['llm_score'], alpha=0.5, label='LLM', bins=5)
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.title('Score Distribution')
plt.legend()
# Subplot 3: Agreement levels
plt.subplot(1, 3, 3)
agreement_data = [
metrics['exact_agreement'],
metrics['within_1_agreement'] - metrics['exact_agreement'],
1 - metrics['within_1_agreement']
]
plt.pie(agreement_data,
labels=['Exact Agreement', 'Within 1 Point', 'Disagreement'],
autopct='%1.1f%%')
plt.title('Agreement Levels')
plt.tight_layout()
plt.show()
return metrics
else:
print(f"Error: {metrics['error']}")
return None
# Example evaluation run
# results_df = benchmark_evaluator.evaluate_dataset(synthetic_dataset)
# analyze_llm_human_correlation(results_df)
5.2 Stability and Repeatability Analysis
class StabilityAnalyzer:
def __init__(self, judge: LLMJudge):
self.judge = judge
def test_repeatability(self, question: str, answer: str, n_runs: int = 5) -> Dict[str, Any]:
"""Test repeatability of LLM evaluations"""
scores = []
explanations = []
for i in range(n_runs):
result = structured_evaluator.evaluate_with_json_output(question, answer)
scores.append(result.get('total_rating', 0))
explanations.append(result.get('evaluation', ''))
return {
'scores': scores,
'explanations': explanations,
'mean_score': np.mean(scores),
'std_score': np.std(scores),
'score_range': max(scores) - min(scores),
'consistency_ratio': len(set(scores)) / len(scores) # Lower is more consistent
}
def analyze_temperature_effect(self, question: str, answer: str, temperatures: List[float]) -> Dict[str, Any]:
"""Analyze effect of temperature on evaluation consistency"""
results = {}
for temp in temperatures:
# Create judge with specific temperature
temp_judge = LLMJudge()
temp_judge.llm.temperature = temp
temp_evaluator = StructuredOutputEvaluator(temp_judge)
# Run multiple evaluations
scores = []
for _ in range(3):
result = temp_evaluator.evaluate_with_json_output(question, answer)
scores.append(result.get('total_rating', 0))
results[f'temp_{temp}'] = {
'scores': scores,
'mean': np.mean(scores),
'std': np.std(scores)
}
return results
stability_analyzer = StabilityAnalyzer(judge)
6. Limitations
The Reality Check: What Can Go Wrong?
While AI judges show tremendous promise, it’s crucial to understand their limitations. Like any powerful tool, they’re not perfect and can fail in specific ways. Understanding these limitations helps us use them more effectively and know when human judgment is still necessary.
Think of AI judges like a very knowledgable but sometimes quirky colleague – they can provide valuable insights most of the time, but you need to double-check their work in certain situations.
6.1 The Main Challenges
1. Bias and Inconsistency: The Hidden Prejudices
AI systems can inherit and amplify biases present in their training data. This means they might unfairly favor certain types of responses or writing styles, or discriminate against content from certain groups or perspectives.
Example: An AI judge might consistently rate formal, academic writing styles higher than casual or conversational styles, even when the casual style is more appropriate for the context.
2. Prompt Sensitivity: Small Changes, Big Differences
AI judges can be surprisingly sensitive to tiny changes in how you ask them to evaluate something. Adding a single word or changing the order of instructions can sometimes lead to dramatically different scores.
Example: "Rate this answer" vs. "Rate this excellent answer" – the word "excellent" might unconsciously bias the AI toward giving higher scores.
3. Inconsistency Over Time
Unlike human teachers who develop consistent grading patterns over years, AI systems can be inconsistent. They might evaluate the same piece of text differently if you ask them on different days or even within the same session.
4. Overconfidence and Hallucination
AI systems often express high confidence even when they’re wrong. They might also “hallucinate” – claiming that a text contains information or makes arguments that aren’t actually there.
Example: An AI judge might confidently state that an answer "provides three clear examples" when the answer actually only provides one example.
5. Limited Domain Expertise
While AI judges can handle many general tasks well, they may struggle with specialized domains that require deep expertise, cultural knowledge, or professional experience.
Example: An AI might not properly evaluate the quality of legal advice, medical information, or culturally specific content.
6.1 Understanding These Limitations in Practice
6.1 Bias and Inconsistency Detection
class BiasDetector:
def __init__(self, judge: LLMJudge):
self.judge = judge
def test_order_bias(self, question: str, answer1: str, answer2: str) -> Dict[str, Any]:
"""Test for position bias in pairwise comparisons"""
# Test A vs B
result_ab = pairwise_evaluator.compare_answers(question, answer1, answer2)
# Test B vs A (reversed order)
result_ba = pairwise_evaluator.compare_answers(question, answer2, answer1)
# Check for consistency
consistent = False
if result_ab.get('winner') == 'A' and result_ba.get('winner') == 'B':
consistent = True
elif result_ab.get('winner') == 'B' and result_ba.get('winner') == 'A':
consistent = True
elif result_ab.get('winner') == 'tie' and result_ba.get('winner') == 'tie':
consistent = True
return {
'ab_result': result_ab,
'ba_result': result_ba,
'consistent': consistent,
'bias_detected': not consistent
}
def test_prompt_sensitivity(self, base_question: str, answer: str, prompt_variations: List[str]) -> Dict[str, Any]:
"""Test sensitivity to prompt variations"""
results = {}
scores = []
for i, variation in enumerate(prompt_variations):
modified_question = f"{base_question} {variation}"
result = structured_evaluator.evaluate_with_json_output(modified_question, answer)
score = result.get('total_rating', 0)
results[f'variation_{i+1}'] = {
'prompt': modified_question,
'score': score,
'evaluation': result.get('evaluation', '')
}
scores.append(score)
return {
'results': results,
'score_variance': np.var(scores),
'score_range': max(scores) - min(scores) if scores else 0,
'high_sensitivity': np.var(scores) > 1.0 # Arbitrary threshold
}
bias_detector = BiasDetector(judge)
# Example prompt variations for sensitivity testing
prompt_variations = [
"", # Base case
"(Please be thorough in your evaluation.)",
"(This is very important.)",
"[Note: Consider all aspects carefully.]"
]
6.2 Hallucination and Overconfidence Detection
class QualityAssurance:
def __init__(self, judge: LLMJudge):
self.judge = judge
def detect_potential_hallucination(self, question: str, answer: str, reference_text: str = None) -> Dict[str, Any]:
"""Attempt to detect hallucinations in evaluation"""
# Get detailed evaluation
result = structured_evaluator.evaluate_with_json_output(question, answer)
# Check for specific red flags
evaluation_text = result.get('evaluation', '').lower()
red_flags = [
'the answer mentions' in evaluation_text and 'mentions' not in answer.lower(),
'the answer states' in evaluation_text and 'states' not in answer.lower(),
'according to the answer' in evaluation_text and len(answer.split()) < 10,
result.get('total_rating', 0) > 4 and len(answer.split()) < 5 # High score for very short answer
]
return {
'evaluation': result,
'potential_hallucination': any(red_flags),
'red_flags_detected': sum(red_flags),
'warning_signs': [
'Mentions content not in answer' if red_flags[0] else None,
'Fabricates statements' if red_flags[1] else None,
'Over-analyzes brief answer' if red_flags[2] else None,
'Unrealistically high score' if red_flags[3] else None
]
}
def confidence_calibration_check(self, evaluations: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Check if confidence scores are well-calibrated"""
# This would require ground truth data
# Simplified version checking for overconfidence patterns
high_confidence_low_quality = 0
total_evaluations = len(evaluations)
for eval_result in evaluations:
confidence = eval_result.get('confidence', 3)
score = eval_result.get('total_rating', 0)
# Flag cases where confidence is high but score is low
if confidence >= 4 and score <= 2:
high_confidence_low_quality += 1
overconfidence_ratio = high_confidence_low_quality / total_evaluations if total_evaluations > 0 else 0
return {
'total_evaluations': total_evaluations,
'high_confidence_low_quality': high_confidence_low_quality,
'overconfidence_ratio': overconfidence_ratio,
'potential_overconfidence': overconfidence_ratio > 0.2 # Arbitrary threshold
}
qa_checker = QualityAssurance(judge)
7. Recommendations & Best Practices
Making AI Judges Work for You: A Practical Guide
Now that we understand both the capabilities and limitations of AI judges, how do we use them effectively in practice? This section provides concrete, actionable guidance based on research findings and real-world experiance.
Think of these recommendations as a recipe for success – follow these principles, and you’ll get much better results from your AI evaluation systems.
7.1 The Essential Guidelines
1. Design Clear, Structured Instructions
Just as you would give detailed instructions to a human evaluator, be specific and clear with your AI judge:
- Be explicit about what you want: Instead of
"rate this answer,"try"rate this answer for accuracy, relevance, and clarity on a 1-4 scale" - Provide context: Explain the task, the audience, and what constitutes a good response
- Use consistent language: Stick to the same terminology and structure across evaluations
2. Choose Appropriate Scoring Scales
Research consistently shows that simpler scales work better:
- Use 1-4 or 1-5 scales instead of complex 1-10 or percentage systems
- Define each score level clearly:
"1 = Poor, 2 = Below Average, 3 = Good, 4 = Excellent" - Avoid too many gradations: Humans (and AI) struggle to meaningfully distinguish between 17 different quality levels
3. Provide Examples When Possible
Show your AI judge what good evaluation looks like:
- Include 1-2 examples per score level for smaller models
- Show both the text being evaluated and the ideal evaluation
- Demonstrate the reasoning process, not just the final score
4. Control for Consistency
Reduce randomness and improve reliability:
- Use low temperature settings
(0.1-0.2)to get more consistent responses - Freeze random seeds when possible
- Consider averaging multiple evaluations for important decisions
5. Validate Against Human Judgment
Never deploy an AI evaluation system without testing:
- Compare AI scores to human scores on a sample of your data
- Look for systematic biases or patterns in disagreements
- Adjust your prompts and criteria based on what you find
7.2 Complete Evaluation Pipeline
Based on these principles, here’s how to build a robust, practical AI evaluation system:
class ComprehensiveEvaluator:
def __init__(self, model_name: str = "llama3.2"):
self.judge = LLMJudge(model_name)
self.structured_evaluator = StructuredOutputEvaluator(self.judge)
self.few_shot_evaluator = FewShotEvaluator(self.judge)
self.bias_detector = BiasDetector(self.judge)
self.qa_checker = QualityAssurance(self.judge)
def comprehensive_evaluation(self,
question: str,
answer: str,
reference_answer: str = None,
use_few_shot: bool = False,
examples: List[Dict[str, Any]] = None) -> Dict[str, Any]:
"""Comprehensive evaluation with all best practices"""
# 1. Primary evaluation
if use_few_shot and examples:
primary_result = self.few_shot_evaluator.evaluate_with_examples(
examples, question, answer
)
# Parse the few-shot result (simplified)
primary_score = 3 # Would need proper parsing
else:
primary_result = self.structured_evaluator.evaluate_with_json_output(
question, answer
)
primary_score = primary_result.get('total_rating', 0)
# 2. Stability check
stability_results = stability_analyzer.test_repeatability(question, answer, n_runs=3)
# 3. Quality assurance
qa_results = self.qa_checker.detect_potential_hallucination(question, answer)
# 4. Compile comprehensive results
results = {
'primary_evaluation': primary_result,
'stability_metrics': {
'mean_score': stability_results['mean_score'],
'std_score': stability_results['std_score'],
'consistency_ratio': stability_results['consistency_ratio']
},
'quality_flags': {
'potential_hallucination': qa_results['potential_hallucination'],
'red_flags_count': qa_results['red_flags_detected']
},
'confidence_assessment': self._assess_confidence(primary_score, stability_results),
'recommendations': self._generate_recommendations(primary_result, stability_results, qa_results)
}
return results
def _assess_confidence(self, primary_score: int, stability_results: Dict[str, Any]) -> str:
"""Assess confidence in the evaluation"""
if stability_results['std_score'] < 0.5:
return "High confidence - consistent scores"
elif stability_results['std_score'] < 1.0:
return "Medium confidence - some variation"
else:
return "Low confidence - high variation"
def _generate_recommendations(self,
primary_result: Dict[str, Any],
stability_results: Dict[str, Any],
qa_results: Dict[str, Any]) -> List[str]:
"""Generate recommendations based on evaluation results"""
recommendations = []
if stability_results['std_score'] > 1.0:
recommendations.append("Consider averaging multiple evaluations due to high variance")
if qa_results['potential_hallucination']:
recommendations.append("Review evaluation carefully - potential hallucination detected")
if primary_result.get('total_rating', 0) <= 2:
recommendations.append("Consider revising the answer based on identified weaknesses")
if not recommendations:
recommendations.append("Evaluation appears reliable and consistent")
return recommendations
# Initialize comprehensive evaluator
comprehensive_evaluator = ComprehensiveEvaluator()
7.2 Ensemble Evaluation
class EnsembleEvaluator:
def __init__(self, models: List[str] = ["llama3.2"]):
self.judges = [LLMJudge(model) for model in models]
self.model_names = models
def ensemble_evaluation(self, question: str, answer: str) -> Dict[str, Any]:
"""Evaluate using multiple LLMs and combine results"""
individual_results = []
scores = []
for i, judge in enumerate(self.judges):
evaluator = StructuredOutputEvaluator(judge)
result = evaluator.evaluate_with_json_output(question, answer)
individual_results.append({
'model': self.model_names[i],
'result': result
})
scores.append(result.get('total_rating', 0))
# Combine results
ensemble_score = np.mean(scores)
score_variance = np.var(scores)
# Determine consensus
consensus = "Strong" if score_variance < 0.5 else "Weak" if score_variance < 1.5 else "No consensus"
return {
'individual_results': individual_results,
'ensemble_score': round(ensemble_score, 2),
'score_variance': round(score_variance, 2),
'consensus_level': consensus,
'recommendation': self._ensemble_recommendation(ensemble_score, score_variance)
}
def _ensemble_recommendation(self, ensemble_score: float, variance: float) -> str:
"""Generate recommendation based on ensemble results"""
if variance < 0.5:
return f"High confidence in ensemble score of {ensemble_score:.1f}"
elif variance < 1.5:
return f"Moderate confidence in ensemble score of {ensemble_score:.1f} - some disagreement between models"
else:
return "Low confidence - significant disagreement between models, consider human evaluation"
# Example with single model (would work with multiple models if available)
ensemble_evaluator = EnsembleEvaluator(["llama3.2"])
7.3 Complete Example Usage
def complete_evaluation_example():
"""Complete example demonstrating best practices"""
# Example Q&A pair
question = "What are the main causes of climate change?"
answer = """Climate change is primarily caused by human activities that increase greenhouse gas concentrations in the atmosphere. The main causes include:
1. Fossil fuel burning (coal, oil, gas) for electricity, heat, and transportation
2. Deforestation and land use changes
3. Industrial processes and manufacturing
4. Agriculture, particularly livestock farming
5. Waste management and landfills
These activities release carbon dioxide, methane, and other greenhouse gases that trap heat in the atmosphere, leading to global warming and climate change."""
print("COMPREHENSIVE EVALUATION EXAMPLE")
print("=" * 50)
print(f"Question: {question}")
print(f"Answer: {answer[:100]}...")
print("\n" + "=" * 50)
# 1. Basic structured evaluation
print("\n1. STRUCTURED EVALUATION:")
basic_result = structured_evaluator.evaluate_with_json_output(question, answer)
print(f"Score: {basic_result.get('total_rating', 'N/A')}")
print(f"Evaluation: {basic_result.get('evaluation', 'N/A')[:200]}...")
# 2. Stability test
print("\n2. STABILITY TEST:")
stability_result = stability_analyzer.test_repeatability(question, answer, n_runs=3)
print(f"Mean Score: {stability_result['mean_score']:.2f}")
print(f"Standard Deviation: {stability_result['std_score']:.2f}")
print(f"Consistency: {'High' if stability_result['consistency_ratio'] < 0.5 else 'Low'}")
# 3. Quality assurance
print("\n3. QUALITY ASSURANCE:")
qa_result = qa_checker.detect_potential_hallucination(question, answer)
print(f"Potential Hallucination: {'Yes' if qa_result['potential_hallucination'] else 'No'}")
print(f"Red Flags: {qa_result['red_flags_detected']}")
# 4. Comprehensive evaluation
print("\n4. COMPREHENSIVE EVALUATION:")
comprehensive_result = comprehensive_evaluator.comprehensive_evaluation(
question, answer
)
print(f"Confidence: {comprehensive_result['confidence_assessment']}")
print("Recommendations:")
for rec in comprehensive_result['recommendations']:
print(f" - {rec}")
return {
'basic': basic_result,
'stability': stability_result,
'qa': qa_result,
'comprehensive': comprehensive_result
}
# Run complete example
# results = complete_evaluation_example()
8. Future Directions
Where Is This Technology Heading?
The field of AI evaluation is rapidly evolving, with exciting developments on the horizon that promise to make AI judges even more reliable, sophisticated, and useful. Here’s what researchers and practitioners are working on:
8.1 The Next Generation of AI Evaluation
Self-Reflection and Improvement
Imagine an AI judge that can critique its own evaluations and improve them. Researchers are developing systems where AI evaluators can:
- Second-guess themselves:
"Let me reconsider this evaluation – was I too harsh?" - Check their own work: Cross-reference their evaluations against multiple criteria
- Learn from mistakes: Adjust their approach based on feedback
This is like having a teacher who continuously reflects on their grading practices and gets better over time.
8.2 Self-Consistency and Reflection
The following code demonstrates how we can build AI systems that evaluate their own evaluations:
class ReflectiveEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
def self_consistent_evaluation(self, question: str, answer: str, n_iterations: int = 3) -> Dict[str, Any]:
"""Multiple evaluation rounds with self-consistency"""
evaluations = []
scores = []
for i in range(n_iterations):
# Different prompting approach each time
if i == 0:
prompt = f"""
Rate this Q&A pair on a scale of 1-4:
Question: {question}
Answer: {answer}
Score:
Reasoning:
"""
elif i == 1:
prompt = f"""
As an expert evaluator, how would you score this answer?
Question: {question}
Answer: {answer}
Consider accuracy, completeness, and clarity.
Score (1-4):
Explanation:
"""
else:
prompt = f"""
Evaluate the quality of this answer:
Q: {question}
A: {answer}
Rating (1-4):
Justification:
"""
response = self.judge.evaluate_text(prompt)
evaluations.append(response)
# Extract score (simplified)
try:
score_match = [int(s) for s in response.split() if s.isdigit() and 1 <= int(s) <= 4]
if score_match:
scores.append(score_match[0])
else:
scores.append(3) # Default
except:
scores.append(3)
# Check consistency
score_mode = max(set(scores), key=scores.count)
consistency_score = scores.count(score_mode) / len(scores)
return {
'individual_evaluations': evaluations,
'scores': scores,
'consensus_score': score_mode,
'consistency_level': consistency_score,
'is_consistent': consistency_score >= 0.67
}
def reflection_based_evaluation(self, question: str, answer: str) -> Dict[str, Any]:
"""Evaluation with reflection step"""
# Initial evaluation
initial_prompt = f"""
Evaluate this Q&A pair:
Question: {question}
Answer: {answer}
Initial assessment (1-4):
Reasoning:
"""
initial_response = self.judge.evaluate_text(initial_prompt)
# Reflection step
reflection_prompt = f"""
You previously evaluated this Q&A pair:
Question: {question}
Answer: {answer}
Your initial assessment was:
{initial_response}
Now reflect on your evaluation. Were you too harsh or too lenient?
Consider if you missed anything important.
Revised assessment (1-4):
What changed in your thinking:
"""
reflection_response = self.judge.evaluate_text(reflection_prompt)
return {
'initial_evaluation': initial_response,
'reflection': reflection_response,
'evaluation_method': 'reflection_based'
}
reflective_evaluator = ReflectiveEvaluator(judge)
8.2 Meta-Evaluation Framework
class MetaEvaluator:
def __init__(self, judge: LLMJudge):
self.judge = judge
def evaluate_evaluation_quality(self,
question: str,
answer: str,
evaluation: str,
score: int) -> Dict[str, Any]:
"""Meta-evaluate the quality of an evaluation"""
prompt = f"""
You are a meta-evaluator. Your job is to evaluate the quality of an evaluation.
Original Question: {question}
Original Answer: {answer}
Evaluation to assess: {evaluation}
Score given: {score}
Assess the evaluation on these criteria:
1. Accuracy: Is the evaluation factually correct about the answer?
2. Completeness: Does it cover all important aspects?
3. Fairness: Is the score justified by the reasoning?
4. Clarity: Is the evaluation clear and well-structured?
Provide your meta-evaluation:
Meta-score (1-4):
Issues identified:
Strengths of the evaluation:
"""
response = self.judge.evaluate_text(prompt)
return {
'meta_evaluation': response,
'original_evaluation': evaluation,
'original_score': score
}
def calibration_analysis(self, evaluations: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Analyze calibration of evaluations"""
# This would be more sophisticated with real data
score_distribution = {}
evaluation_lengths = []
for eval_data in evaluations:
score = eval_data.get('score', 0)
evaluation = eval_data.get('evaluation', '')
score_distribution[score] = score_distribution.get(score, 0) + 1
evaluation_lengths.append(len(evaluation.split()))
return {
'score_distribution': score_distribution,
'avg_evaluation_length': np.mean(evaluation_lengths),
'evaluation_length_std': np.std(evaluation_lengths),
'potential_issues': self._identify_calibration_issues(score_distribution, evaluation_lengths)
}
def _identify_calibration_issues(self, score_dist: Dict[int, int], eval_lengths: List[int]) -> List[str]:
"""Identify potential calibration issues"""
issues = []
# Check for score bunching
if len(score_dist) <= 2:
issues.append("Limited score range - possible anchoring bias")
# Check for extreme skewing
total_evals = sum(score_dist.values())
if score_dist.get(4, 0) / total_evals > 0.7:
issues.append("Possible leniency bias - too many high scores")
if score_dist.get(1, 0) / total_evals > 0.7:
issues.append("Possible severity bias - too many low scores")
# Check evaluation length consistency
if np.std(eval_lengths) > np.mean(eval_lengths):
issues.append("Inconsistent evaluation depth")
return issues if issues else ["No major calibration issues detected"]
meta_evaluator = MetaEvaluator(judge)
Conclusion
The Revolution in AI Evaluation: What It Means for Everyone
The emergence of LLMs as automated evaluators represents one of the most significant advances in artificial intelligence evaluation methodology. We’ve moved from simple pattern-matching algorithms to sophisticated AI systems that can understand context, reason about quality, and provide detailed, interpretable feedback.
The Key Takeaways
For Non-Technical Users:
- AI evaluation is becoming mainstream: You don’t need to be a programmer to benefit from these systems
- Quality is approaching human levels: Modern AI judges often agree with human experts 80-85% of the time
- It’s not perfect, but it’s practical: While AI judges have limitations, they’re already good enough for many real-world applications
- Human oversight remains important: These systems work best when combined with human judgment, not as replacements for it
For Technical Teams:
- Implementation is becoming straightforward: Tools like Ollama and models like Llama 3.2 make deployment accessible
- Best practices matter enormously: Following proven guidelines for prompting, scoring, and validation dramatically improves results
- Systematic testing is essential: Always validate your AI evaluation system against human judgments before deployment
- Consider ensemble approaches: Using multiple models or evaluation strategies often yields better results
Real-World Impact
This technology is already transforming how organizations approach quality assessment:
In Education: Schools are using AI judges to provide instant feedback on student writing, freeing teachers to focus on higher-level instruction and mentoring.
In Customer Service: Companies are evaluating chatbot responses at scale, ensuring consistent quality across millions of customer interactions.
In Content Creation: Publishers and media companies are using AI evaluation to maintain editorial standards while scaling content production.
In Software Development: Development teams are automatically evaluating code quality, documentation, and user experience at speeds impossible with human review alone.
Looking Forward: The Responsible Path
As this technology continues to improve, the key to success lies in thoughtful, responsible implementation:
- Start small and validate: Test AI evaluation systems on manageable datasets before scaling up
- Maintain human oversight: Use AI judges to augment human decision-making, not replace it entirely
- Be transparent about limitations: Understand and communicate where AI evaluation might fall short
- Invest in continuous improvement: Regularly update and refine your evaluation systems as better techniques emerge
The Bottom Line
LLM-as-judge represents a significant step toward making high-quality evaluation scalable, consistent, and accessible. While not a perfect solution, it offers substantial benefits over traditional approaches and continues to improve rapidly.
For organizations dealing with large volumes of text evaluation – whether that’s customer feedback, content quality assessment, educational grading, or AI system development – these techniques offer a practical path forward that balances automation with quality.
The future of AI evaluation is bright, and the tools to implement these systems effectively are available today. The question isn’t whether this technology will transform how we evaluate text quality, but how quickly and thoughtfully we can integrate it into our workflows.
Final Practical Advice
Conclusion
LLM-as-judge represents a significant advancement in automated evaluation of natural language generation outputs. While not without limitations, the approach offers substantial benefits:
- Scalability: Can evaluate thousands of outputs quickly
- Flexibility: Adaptable to various tasks and criteria
- Interpretability: Provides detailed reasoning for scores
- Cost-effectiveness: Reduces need for human annotation
Key best practices include:
- Careful prompt design with clear rubrics
- Use of structured output formats
- Temperature control for consistency
- Validation against human judgments
- Awareness of potential biases and limitations
The field continues to evolve rapidly, with promising directions including self-consistency techniques, specialized judge training, and meta-evaluation frameworks. As LLM capabilities improve, we can expect even stronger alignment with human judgment while maintaining the scalability advantages.
Final Practical Advice
If you’re considering implementing AI evaluation in your organization:
- Start with a pilot project: Choose a well-defined use case with clear success criteria
- Invest time in prompt engineering: The quality of your instructions directly impacts the quality of evaluations
- Build in validation from day one: Plan how you’ll measure and improve your system’s performance
- Document everything: Keep records of what works, what doesn’t, and why
- Stay connected to the research: This field is evolving rapidly – new techniques and improvements appear regularly
The combination of powerful AI models, practical implementation tools, and proven best practices makes this an opportune time to explore AI-powered evaluation systems. With careful planning and thoughtful implementation, these systems can provide significant value while maintaining the quality and reliability that your applications demand.
# Final utility function for easy usage
def quick_evaluate(question: str, answer: str, model: str = "llama3.2") -> Dict[str, Any]:
"""Quick evaluation function for easy usage"""
temp_judge = LLMJudge(model)
temp_evaluator = StructuredOutputEvaluator(temp_judge)
result = temp_evaluator.evaluate_with_json_output(question, answer)
return {
'score': result.get('total_rating', 0),
'evaluation': result.get('evaluation', ''),
'detailed_scores': result.get('scores', {}),
'model_used': model
}
# Example usage:
# result = quick_evaluate("What is AI?", "AI is artificial intelligence used in computers.")
# print(f"Score: {result['score']}, Evaluation: {result['evaluation']}")
References
- ar5iv.labs.arxiv.org - Traditional metrics for open-ended text generation and their limitations
- ar5iv.labs.arxiv.org - Human evaluation as ground truth and scalability challenges
- ar5iv.labs.arxiv.org - LLMs as judges paradigm and evaluation modes
- arxiv.org - Agreement with human judgments approaching human–human agreement
- huggingface.co - Automated evaluation for NLG tasks
- ar5iv.labs.arxiv.org - Pointwise, pairwise, and listwise evaluation modes
- arxiv.org - Pointwise rating and Likert scale evaluation
- ar5iv.labs.arxiv.org - Pairwise preference evaluation methods
- ar5iv.labs.arxiv.org - Listwise ranking approaches
- ar5iv.labs.arxiv.org - Linguistic quality criteria
- arxiv.org - Validation against human judgments
- arxiv.org - LLM evaluation power and effectiveness
Note: All images in this article were generated using Google Gemini AI.